
7月19日,不管是跨国企业还是个人用户,惊诧地发现自己的Windows电脑或移动设备,在毫无预先征兆的情况下出现了“死亡蓝屏”,对于熟悉使用Windows系统的人都知道,“蓝屏”意味着电脑系统碰到了较为严重的技术性故障,之前未保存的工作进度或许无法恢复。
不久之后人们发现,这并不是一起局部的、偶发性的“蓝屏事件”,而是影响到全球底层IT系统的大规模事故,机场无法正常更新航班信息、航空公司无法出具登机牌、酒店无法登记入住、911无法接警、电视台直播中断、银行存取款业务暂停。
很快事件发生的原因水落石出,一家名为CrowdStrike的网络安全公司在Windows系统上的一次小小的升级,导致了整个系统的崩溃。该公司首席执行官在第一时间对外澄清,事故本身并不是网络安全事件,而是软件的升级故障。他表示,已经发布了故障解决方案,但由于该方案需要许多手动的操作,因而影响可能还将持续一段时间。
这一全球范围“蓝屏”事件,已经被许多媒体定性为史上最大规模的IT技术故障事故,由于影响到的范围极为广泛,由此带来的直接和间接经济损失巨大,造成的负面影响和冲击,可能远超一次大规模黑客攻击。
作为“罪魁祸首”的CrowdStrike公司已经受到了“惩罚”,该公司股价当天下跌超过11%。但这家公司面临的麻烦可能还远未终结,对于事故的责任认定目前还没有明确的结论,CrowdStrike未来或将遭遇大规模的索赔。
从更大的意义上来看,此次事件也再一次警醒:我们所习以为常的现代便利生活,过于依赖单一的系统,一旦该系统出现故障,将会在瞬间导致经济生活陷入停滞甚至濒临崩溃,如何避免这样的突发性事件再度发生?可能有更多底层性的话题值得探讨。
软件更新导致全球大范围Windows设备陷入“死亡蓝屏”
本周五,微软Windows“蓝屏”事件席卷全球。许多人发现自己的Windows电脑突然进入“死亡蓝屏”,无法正常工作,甚至重启都不能解决问题。
这一问题不仅仅局限于个人用户,实际上,许多用Window系统的企业用户未能幸免,甚至影响到更大规模的服务器层面,航空公司、酒店、银行等服务业的正常运转受到影响,航空公司无法更新行程信息,导致航班延误、旅客的登机牌无法正常出具、酒店无法完成客人的入住及离店手续、银行也无法进行正常的业务,甚至连英国天空电视台的直播也被迫中断了数小时之久。在美国的某些地区,911报警系统甚至无法正常工作。
这一轮影响广泛的“蓝屏”事件,起因并非是微软的Windows系统本身出了问题,而是第三方网络安全公司CrowdStrike公司的一项更新所导致。微软方面发布的声明称,“我们可以确认影响Windows设备的是CrowdStrike的Falcon客户端,这可能导致系统卡在重启阶段”,微软方面称,CrowdStrike方面已经撤回了受影响的更新。
CrowdStrike方面随后也给出了回应,该公司首席执行官George Kurtz称,公司正在与受到影响的客户共同解决。Kurtz表示,此次大规模Windows系统宕机,并不是一项安全事件或者网络攻击,而是一项独立事件,并且解决方案已经发布。
尽管根据CrowdStrike方面称解决方案已经发布,但从用户角度来看,由于该公司公布的解决方案是繁琐的手动过程,因此对于一些大规模的系统和服务器来说,完全恢复正常运行,可能还需要花费很长时间。
对经济社会活动的影响冲击巨大
全球性“宕机”事件发生后,作为”罪魁祸首”的安全公司CrowdStrike公司股价立即出现大幅下跌,盘前便出现14%以上的跳水,19日全天跌幅超过11%。毫无疑问,CrowdStrike造成这一全球性安全事件令投资者对其未来业绩信心产生了极大的动摇。
然而这桩突发事件所造成的影响和冲击,远远不至于这一家公司。理论上,任何正常业务由于“宕机”事件受到影响的公司、行业以及这些公司和行业所服务的客户都直接受到影响。
首先影响最为直观和显著的是民航业,由于“宕机”事件,航空公司的系统无法正常运行,许多机场出现大批旅客滞留现象。根据航班监测网站Flightaware的数据显示,在美国,19日当天就有超过2000架次航班被取消,另外有5373架航班被延误。在全球范围内,截止到美国时间19日晚间,总共有超过2.9万航班延误。
除了民航系统,其他交通、物流运输等形式也受到影响,例如美国首都华盛顿特区的地铁系统在19日当天关闭了数个小时,美国最大的快递服务UPS和联邦快递也出现服务延迟的情况。
此外、酒店住宿、旅游、金融、医疗服务,甚至美国的部分地区,包括阿拉斯加、亚利桑那、印第安纳、俄亥俄的911服务也遭遇中断。
尽管目前无法准确估量对经济的影响规模究竟有多大,但毫无疑问,上述所有被影响的公司、行业以及相应的客户等,都将对整个经济产生极大的负面影响。现代社会平日里习以为常的正常运转,只是因为一个小小的软件升级Bug,就立即陷入了全面瘫痪,这不得不说是一件非常可怕的事。
目前对于事件的责任认定还没有明确的结论,CrowdStrike是否应该承担由此造成的损失?如果全部由CrowdStrike承担,或许这家公司将无力负担巨额的赔偿,过程中是否会有保险公司的介入,目前这些信息还未可知,但事件本身将会引发更多的思考和讨论,正如《黑天鹅》作者Taleb在事件发生后评论称,一个单点的失误就造成了全局的瘫痪,凸显了系统的脆弱性。如何应对这样的脆弱性,避免整个经济活动在毫无应对的情况下陷入瘫痪,是一个更为急迫的话题。
一次软件更新如何导致全球电脑崩溃?CrowdStrike前员工自愿背锅
7月20日消息,据国外媒体报道,历史上,只有少数几次出现过一段代码瞬间瘫痪全球计算机系统的事件。然而,过去12小时撼动全球互联网和IT基础设施的持续性数字灾难,似乎不是由黑客发布恶意代码引发的,而是由旨在阻止网络攻击的安全软件更新所致。那么一次有缺陷的内核驱动程序更究竟是如何导致全球计算机陷入重启死亡螺旋的,又是如何导致航空旅行、医院、银行等瘫痪的?

周五,两起重大互联网基础设施故障接踵而至,导致从机场、交通系统到银行、医院、酒店及媒体机构等多个领域网络服务全面中断。先是周四晚间微软Azure云平台遭遇大范围服务中断,紧接着周五早晨,网络安全巨头CrowdStrike发布的一则带缺陷软件更新,将大量Windows设备拖入了无休止的重启循环,二者共同编织了一场网络风暴。
微软虽已声明这两起事件间无直接联系,但造成这两起灾难之一的原因已经很清楚了:CrowdStrike安全软件Falcon更新中的错误代码是导致这场灾难的核心因素之一。
01 安全软件定期自动更新惹祸
Falcon本质上是一个杀毒平台,可以在笔记本电脑、服务器和路由器等“端点”上深度访问系统,以检测恶意软件和可能代表威胁的可疑活动。然而,由于CrowdStrike不断向系统中添加检测功能,以抵御新的和不断出现的新威胁,因此Falcon需要获得定期自动更新的许可。然而,这种安排的不利之处在于,这一旨在加强安全和稳定的机制最终可能会破坏安全与稳定。
网络安全公司WithSecure首席研究官米科·海普宁(Mikko Hyppönen)说:“此宕机事件规模空前,全球工作站如此大范围的中断实属历史罕见。”他回顾称,十年前,网络蠕虫与木马肆虐,大范围中断尚属常态;而今,全球性的服务中断则更多聚焦于系统的“服务器端”,归咎于如亚马逊AWS等云服务提供商的问题、互联网链路中断、身份验证故障或DNS服务异常等。
CrowdStrike首席执行官乔治·库尔茨(George Kurtz)周五承认,此次危机源自该公司为Windows平台发布的软件代码中存在的“缺陷”,而Mac与Linux系统没有受到影响。他在官方声明中指出:“问题已被迅速识别、隔离,且修复措施已部署完毕。”他补充说,这一系列问题非网络攻击所致。面对媒体,库尔茨诚挚道歉,并坦言系统全面恢复可能需要一定时间。

安全与IT领域的分析师正深入探究此次大规模宕机的根源,他们普遍认为其与CrowdStrike Falcon软件的“内核驱动程序”更新有关。内核驱动程序是连接应用程序与Windows操作系统核心(即内核)的桥梁,赋予了安全软件在系统最底层运行的特权,这对于在恶意软件入侵前进行拦截至关重要。随着恶意软件技术的不断进化,安全软件也必须持续升级其连接性和控制范围以应对挑战。
然而,Magnet Forensics的检测工程主管马修·苏彻(Matthieu Suiche)警示,这种深度访问权限同样伴随着高风险,即安全软件或其更新可能意外导致整个系统崩溃。他将在操作系统内核级别运行恶意代码检测软件比作“开胸手术”。
在网络安全领域拥有23年经验的资深专家康斯丁·拉伊乌(Costin Raiu),曾在卡巴斯基领导威胁情报团队,他对此次事件表示震惊。他指出,在卡巴斯基,Windows软件的驱动程序更新会经历极其严格的审查和多轮测试,持续数周之久,以确保其稳定性与安全性。因此,一个内核驱动程序的更新能引发如此广泛且严重的全球计算机崩溃,确实出乎意料。
更为重要的是,业内呼吁微软加强对相关代码的审查,并实施加密签名机制,这一举动隐含了微软可能同样未能察觉CrowdStrike Falcon驱动程序中的致命漏洞。拉伊乌说:“尽管我们对驱动程序更新保持高度警觉,但此类事件仍时有发生,令人感到惊讶。一个小小的漏洞足以引发连锁反应,摧毁一切,这正是当前局面的真实写照。”
微软一位发言人承认:“CrowdStrike的更新确实导致了全球范围内众多IT系统的瘫痪,但微软并未直接监督CrowdStrike在其平台上的更新流程。”然而,该发言人并未明确回应微软是否对涉及的内核驱动程序更新进行了独立审查。
拉伊乌进一步指出,CrowdStrike并非个例,安全领域的众多公司,包括卡巴斯基乃至微软自家的Windows Defender,在过去几年中都曾通过驱动程序更新不慎触发了Windows系统的蓝屏死机问题。他解释称:“几乎每一个安全解决方案在其发展历程中都会遭遇这样的挑战时刻。这并非新鲜事,只是影响范围和后果有所不同罢了。”
02 诸多因素引发连锁反应
全球网络安全机构迅速响应,纷纷发布针对此次大规模宕机事件的紧急警报。但在CrowdStrike首席执行官正式表态之前,业界专家已基本达成共识:此次全球性的宕机事件非网络攻击所为。然而,其规模之广仍属罕见,主要归因于CrowdStrike Falcon软件的广泛应用及其对Windows系统的高度控制权。
英国国家网络安全中心首席执行官费利西蒂·奥斯瓦尔德(Felicity Oswald)说:“经国家网络安全中心的评估,这些事件与恶意网络攻击无关。”澳大利亚官方亦持相同立场。
约克大学安全自治研究所的约翰·麦克德米德(John McDermid)教授指出:“CrowdStrike的安全软件普及率极高,广泛部署于众多特定类型的机器上,因此,一旦安全软件出现故障,便有可能同时影响大量计算机的正常运行。”
墨尔本大学计算机与信息系统学院的托比·默里(Toby Murray)教授则强调:“Falcon软件拥有极高的权限,能够深度影响所安装计算机的行为,这也是其影响力如此巨大的原因之一。”
澳大利亚珀斯默多克大学IT学院院长戴夫·帕里教授(Dave Parry)指出:“由于CrowdStrike的广泛影响力,这一事件已演化为全球性现象。众多企业及组织依赖其检测和防御威胁,因此,此次问题波及范围极广,影响深远。这并非网络攻击,而是两款软件间的意外交互所致。”
亚特兰大网络安全公司Errata Security的首席执行官罗伯特·格雷厄姆(Robert Graham)强调:“CrowdStrike等网络安全软件因需深入操作系统核心以抵御攻击,一旦出错,其引发的宕机规模往往更为庞大,甚至可能触发连锁崩溃。这或许是我们所见证过的最为严重的IT故障之一。”
此次灾难性事件不仅凸显了互联网的脆弱性,也揭示了其深度互联带来的潜在风险。众多安全专家表示,他们早已预见并努力预防类似CrowdStrike事件的发生,试图防止防御软件本身因被恶意利用或人为失误而引发的连锁故障。牛津大学教授、前英国国家网络安全中心负责人夏兰·马丁(Ciaran Martin)指出:“这一事件深刻揭示了全球数字生态及核心互联网基础设施的脆弱性!”
03 网络安全领域过度依赖少数公司?
CrowdStrike成立于2011年,为数以万计的客户提供抵御网络攻击的软件,其中包括财富500强中的300家公司。市场研究公司Gartner的数据显示,按收入计算,CrowdStrike占安全软件市场份额的15%,这意味着它的软件被广泛应用于各种系统。
然而,一次常规的软件更新竟能引发如此规模的破坏,仍令资深安全专家拉伊乌感到不解。他推测,Falcon软件的更新可能触发了网络基础设施中其他组件的连锁反应,导致灾难性后果倍增。拉伊乌指出:“CrowdStrike虽规模庞大,但其影响力远不止于此。从机场到关键基础设施,再到医疗机构,不可能每个角落都依赖CrowdStrike。我倾向于认为,这是多重因素交织的结果,一个级联效应,一连串的连锁崩溃。”
伦敦大学学院计算机科学系的助理教授玛丽·瓦塞克(Marie Vasek)也强调全球技术系统对少数几家科技公司软件的过度依赖,特别是微软与CrowdStrike。她说:“问题的核心在于,微软作为行业标准软件,几乎无处不在。而CrowdStrike的漏洞一旦暴露,便迅速蔓延至各个系统,揭示了全球技术生态的脆弱性。”

瓦塞克指出,随着技术网络的日益庞大、复杂与紧密相连,一行简单的软件代码错误便可能触发整个计算机网络的崩溃。她与其他信息技术专家共同强调,鉴于CrowdStrike的数字防护被视为不可或缺,其技术在众多计算机系统中享有优先使用权。因此,一旦CrowdStrike软件出现问题,其访问特权将加剧系统瘫痪的风险。
瓦塞克呼吁微软与CrowdStrike双方深入审查其程序流程,以避免此类广泛的技术故障重演。她说,CrowdStrike应审慎规划软件更新策略,确保安全无误地部署至数百万计算机网络。同时,微软也需加大力度,保障其他公司软件更新不会对Windows系统的稳定性造成负面影响,并探索更有效的机制来验证软件兼容性与稳定性。
海普宁暗示,CrowdStrike可能发布了与测试版本不符的软件,或是在更新过程中发生了文件混淆,亦或是多种因素共同作用的结果。他强调,此类软件必须经过严格的测试流程,这是他们以及CrowdStrike需要共同遵循的原则。他指出,安全软件的更新频率极高,因此必须格外小心,确保每次发布的内容都准确无误,这无疑是一项极具挑战性的任务。
尽管宕机事件的影响尚未完全消散,且部分问题的解决仍在进行中,但问题的特性决定了受影响的个别机器可能必须依赖手动重启,而非自动化流程。CrowdStrike首席执行官库尔茨在采访中称:“部分系统可能需要较长时间方能自动复原。”
CrowdStrike最初提出的“临时解决方案”建议Windows用户以安全模式启动系统,删除特定文件后再行重启。然而,海普宁指出:“截至目前,我们观察到的修复方法意味着每台机器都需要人工检查,鉴于全球范围内数百万台设备受到影响,这一过程可能需要数日之久。”
随着系统管理员们争分夺秒地控制事态发展,如何防范未来类似危机的更深层次问题——即存在性挑战——愈发凸显。网络安全咨询机构Hunter Strategy的研发副总裁杰克·威廉姆斯(Jake Williams)强调:“此次事件或促使人们重新审视并调整现有运营模式。CrowdStrike的案例,无论好坏,都鲜明地揭示了未经IT部门审核便推送更新的不可持续性。”
04 Crowdstrike前员工自愿背锅?
海普宁“猜测”,此次问题可能源于更新过程中的“人为失误”。他半开玩笑地表示:“CrowdStrike的一位工程师今天可能过得不太顺利。”
此前,一位名为文森特·弗莱布斯提尔(Vincent Flibustier)的CrowdStrike前员工跳出来,在社交媒体上发帖宣称对微软宕机事件负责。他写道:“在CrowdStrike的第一天,我推送了一项更新,随后下午稍作休息。”此言一出,立即引发了广泛关注。
紧接着,他又发布了一条推文,宣称对自己被解雇“极度不公”。他还附上了一段视频,试图解释整个事件的来龙去脉,并透露:“我正等待着解雇通知的到来。”
在后续的一条推文中,弗莱布斯提尔甚至@了特斯拉首席执行官埃隆·马斯克(Elon Musk),询问对方是否有合适的职位空缺。
然而,弗莱布斯提尔的这一说法并未得到所有人的认同。有网友指出,另一名X用户@nixcraft也分享了类似的经历,声称自己在CrowdStrike工作的第一天就“开始推送核心代码”。
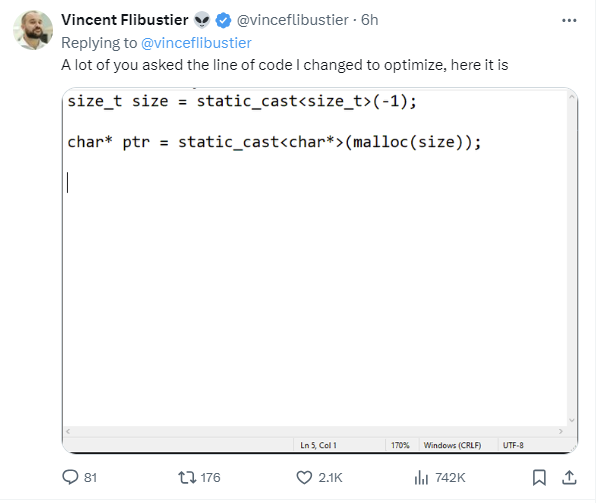
面对这一情况,弗莱布斯提尔调整了他的X上简介,现在写道:“CrowdStrike前员工,因不公正原因遭解雇,仅因优化目的修改了一行代码。现寻求系统管理员职位。”


